Programming Fundamentals Part 4: Logic And Errors
This article series is based on rough drafts of what I intend to eventually turn into a series of lectures and courseware for my brogrammers and siscripters out there. Feedback is welcome, and if it proves useful, I would be happy to list you as a contributor.
2020 UPDATE: I have put together a course for Java which introduces the concepts I have described in these articles, but in greater depth and clarity. If you like my writing, I think you will love my video lectures:
Working Class Java: A Beginner’s Guide To OOP & Software Architecture Udemy Link| Skillshare Link w/ Free Trial
Contents
1. What Is A Program? — A set of instructions to be executed by an Information Processing System
2. The Problem Domain — How to design a program/application
3. Storing Information — How to Model Information (data) in an Information Processing System.
4. Logic And Errors — The two (primary) types of logic in an Information Processing System; how to handle errors properly
5. Separation Of Concerns — The most important Software Architecture principle I have ever come across
6. Proving Programs With Tests — An explanation of the theory, practice, and benefits of testing your software, and applying Test Driven Development
In previous sections, I placed a strong emphasis on the nature of information. In Part 2, my emphasis was on explaining (in the most practical terms I could muster) how to establish a Problem Domain, and how that process is the way in which you can begin to design a program. For Part 3, my emphasis was on explaining how modern era computing systems store information, and how us programmers instruct the computer to do so.
I doubt this is news to you, but it is of equal importance that our Information Processing Systems also be capable of changing, creating, and destroying that information; not simply storing and retrieving it.
To review Part 1 for a moment, I included a graphic of the Von Neumann architecture, which is still in use by the majority of the computing systems you have ever used (at least in principle):
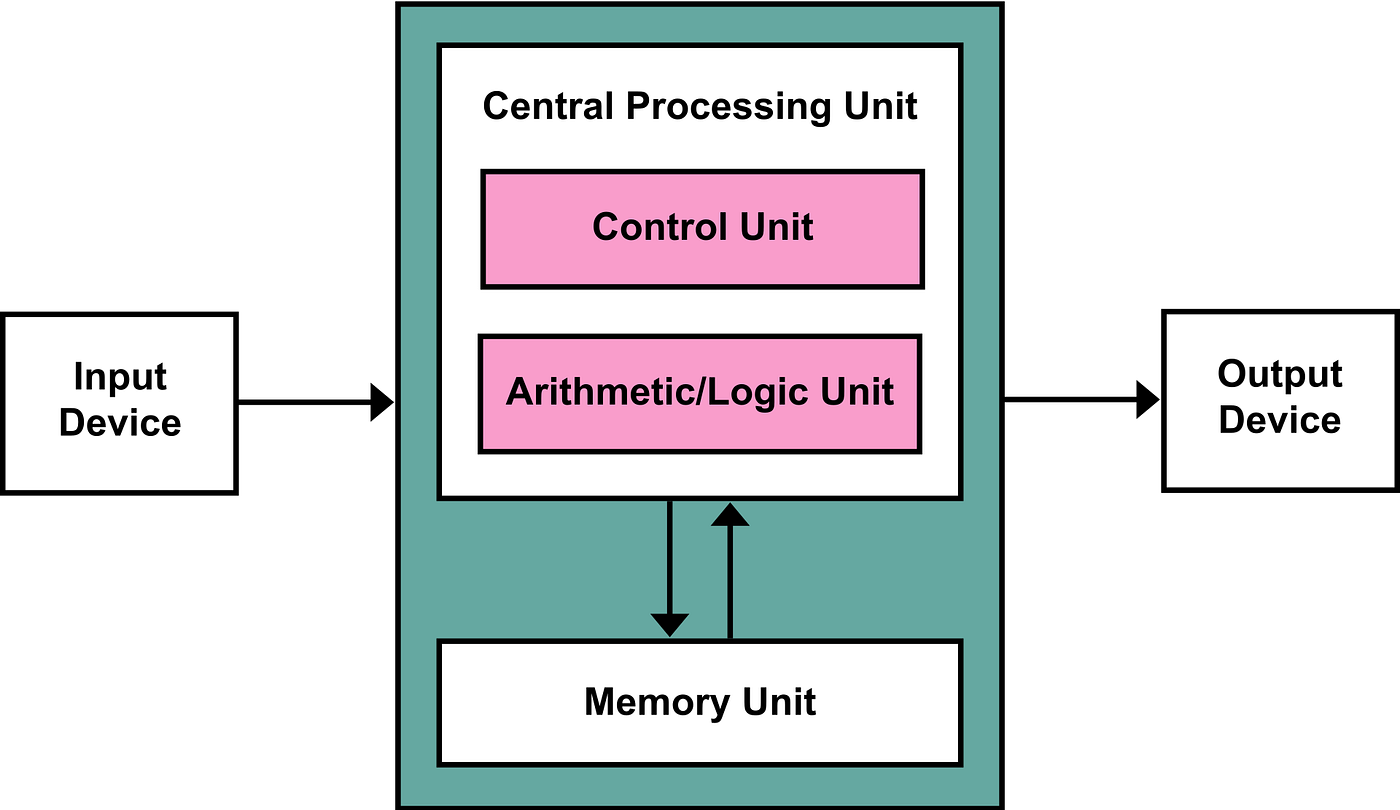
Leaving aside I/O Devices (as the CPU does not care what they are as long as they know how to send and receive messages), we see that there are three fundamental separations in the roles of such systems:
- Memory for storing information (values and variables) [1] Note
- Logic which coordinates the flow of information between different parts of the system (Control)
- Logic which manipulates the information itself (Computation)
Before I proceed further, there are clearly some overloaded definitions in the above diagram and my bullet points, so let me attempt to clear this up. By Logic, I mean Decision Making Capacity. I do not mean to imply that the Control Unit and Arithmetic/Logic Unit perform the same operations exactly, but I do mean to imply that what they do is ultimately about making decisions, or applying logic, to whatever information is within their immediate grasp.

At least in a general sense, there exists a division of two forms of logic which concern us programmers, and my goal in this article is to discuss this division. I have chosen to name these two forms as:
- Computation Logic: Logic which manipulates real-world information over time (such as performing arithmetic to solve an expression). This is similar to what is called “Business Logic” in software development jargon.
- Control Logic: Logic which dictates building, managing, and coordinating the flow of the program itself, such as sending operands and operators to the computation logic, receiving the result, and passing it to a user interface (or some other output device). This is similar to what is called “Application Logic” in software development jargon.
Although I regret once again giving new names to old concepts, the truth is that I do not like the terms “Business Logic” and “Application Logic” at all. Not all applications have anything to do with business (insofar as that word is typically understood in the English language), yet all the logic you write is written in your application. I get what the idea behind these terms is in the context of a software development firm, but I maintain that they are still misleading at worst, and clumsy at best in describing the concepts behind the names.
In any case, I am not implying that you should use my names either; I simply tried to go with what I believe describes the concepts well.
I must make one final and rather unfortunate, but very important preamble. It would be really wonderful if we could always keep control Logic separate from computation Logic, but the truth is that in more complicated programs, it can be tedious and nigh-impossible to do so. In any case, the general prescription to this problem is to rigorously apply separation of concerns. What, how and why is the subject of the next article.
Computation Logic
As mentioned above, computation logic is concerned with changing and examining information in accord with the functions (verbs) which you have established in your problem domain analysis, such as via a problem statement:
“My program will display the result of solving valid binomial expressions limited to addition, subtraction, multiplication, and division. If an expression is invalid, an error message will be displayed instead of the result of solving the expression.”
Now, I must immediately point out that we should not assume every function (verb) which is present in the problem statement should be considered as computation logic. Displaying a result, while certainly indicating that a function is required, does not imply any necessity of the information being computed (in the sense of being changed or examined). Solving and validating expressions are what I am concerned about in this particular example.
Suppose hypothetically, that every computer understood programs written in a single universally compatible high-level programming language. Suppose as well, that the pseudo-code below happens to be written in this hypothetical language:
//1 for true, 0 for false
function validateOperator(Character operator) returns: '1' or '0' {
if (c equals "+") return 1
if (c equals "-") return 1
if (c equals "/") return 1
if (c equals "*") return 1 return 0
}function sum(Number operandOne, Number operandTwo) returns: Number
{
return operandOne + operandTwo
}//...and so forth
Assuming our hypothetical, the above functions could be copy and pasted in to any program ever written (which happens to require solving these same problems), and they would work properly. In a sense, there are no instructions within them which make any reference to, or possess any requirements of, the program which uses them. They satisfy their respective aspects of the problem statement, and they will never need to be modified based on what program or hardware system happens to use them use them. If they do not work, it is entirely because of a problem with the program or system, which cannot reasonably be accounted in the context of these functions.
I won’t discuss it in detail here, but I am secretly telling you to separate out computational logic functions to make them what are known as “Pure Functions” in Functional Programming jargon. I will revisit this concept in Part 7 which discusses using Tests to prove your programs in the same way that a mathematician proves their formulas.
Always do your best to identify and keep computational logic separate from control logic! In small scale programs, this can be achieved by creating a separate Thing (class, struct, object, whatever) and/or Function for each distinct computational operation. It is okay to group conceptually related operations together in Things, but you should still try to break down individual computations into distinct Functions to avoid ugly, hard to read, and hard to test code.
In large scale programs, we can apply these same principles to the different sub-systems (groups of conceptually related Things), giving them specific roles and responsibilities and ensuring that they do not violate them.
Control Logic
Using the same problem statement as an example, let us examine the other functions present:
“My program will display the result… If an expression is invalid, an error message will be displayed instead ”
Whereas a good indicator that something ought to be considered computational logic, is that it does not know or reference anything about the program which uses it, nor the outside world (such as Input/Output devices like mice and monitors), control logic all about that s***.
When we say “display the result”, that implies that there must be some device (or part of the program which does the work of talking to a device) which must ultimately render this result in reality. The simplest form of the output device is a garden variety text-based console or terminal, but if you plan on developing applications for users beyond Linux nerds (which appears to be what I am turning in to gradually), you may need to write different sets of display functions for:
- On-screen widgets, text boxes, labels, graphics, animations, and so forth
- Converting the result into output in an audio format via an enunciator (think text-to-speech)
- All of the above and more, at the same time
There are plenty of other forms which control logic can take beyond input/output work, but this should be a familiar case to anyone who writes applications which are used by human beings. Other examples include, but are not limited to:
- Sending and receiving information to and from various Things and/or Functions which perform operations like arithmetic and validation
- Deciding what particular user interface screen to show to the user based on the last page they visited, what kind of account they possess, whether their login was successful or not, and so forth
Error Handling
Another form of control logic, error handling, happens to be one of the most poorly explained concepts I have ever come across in computing. If I was to imagine a familiar scenario where a student asks a teacher about error handling, it would go something like this:
Student: How do I handle errors in my Java programs?
Teacher: Use “try {//…} catch (exception: Exception) {//…}”
Student: Okay, but what do I do after that?
Teacher: Uhhhh… it depends. Don’t worry though, it won’t be on the test.

In fairness, “it depends” is not a wrong answer; just a bad answer. In any case, let me start by briefly explaining try-catch. I will use Java syntax, but the syntax is quite similar across various modern languages:
try { database.saveDataToDevice(someData)} catch (exception: IOException) {system.out.println("Unable to save user data.")}
There are only two moving parts here:
- A function is called which may fail to do what you expect it to do, but at least it has the courtesy to tell you of this failure by spitting out an “Exception” or “Error”
- If it does fail, we are given some details about what happened (sometimes exact details, sometimes all we know is that it failed)
The “catch” block is where we tell the program what to do in the event that a failure occurs. Now, it is worth dividing the kinds of failure events into two categories:
- Recoverable Errors: These kinds of failure events are those which might briefly interrupt the program’s typical/preferred execution, but they do not necessarily require aborting the user’s current progress or killing the program entirely. For example, you are not going to be using a web browser if there is no network connection present, but that does not mean the browser ought to cause a BLUE SCREEN OF DEATH as a result.
- Nonrecoverable Errors: I think you can guess what this means. Now, sometimes this means to abort the current user session and start anew (which kind of borders on recoverable depending on how patient your user happens to be), but I am mostly thinking of program/device crashing failures. NullPointerException is a classic example, and it is basically is the OS telling you: “Hey dumbass, you told me to look up something in this place in memory, but it did not exist.”
Regarding the errors which you can do something about at runtime, the way in which you determine how to handle the error should be based on asking questions like:
- Does the user need to know something?
- Does the program need to send the user to a specific point in the program’s intended execution (previous page, or previous step in the setup wizard)?
- Should the program try the operation a second time, or n number of times until the user closes it?
- Does some transaction of information (such as sending or receiving bank account balances) need to be undone?
It does depend, but the sad truth is that I have seen many developers, and their projects, that could not handle errors properly even if they wanted to. This is because they write programs as giant incoherent blobs which preclude the ability to jump the user back to anything but the very beginning; let alone more complicated situations. That is of course more of an architectural concern, which we discuss in subsequent articles.
Summary/Damage Control
The main purpose of this article was to discuss the different kinds of “logic” which one will need to write in just about every program. I did my best to point out that some kinds of logic can remain unchanged quite regardless of what program, or computer (with whatever IO devices) they happen to be in. This form of logic is especially easy to test, as we will soon see.
The other form of logic is quite dependent on what is going on in a particular program, and the side-effects on the real world which occur during the program’s normal, or even abnormal execution. I consider Error Handling, to be a subset of this form of logic, but I wanted to try and correct some of the damage done to me as a student on that particular topic by giving it plenty of discussions.
While that will hopefully satisfy the beginners out there somewhat, I strongly anticipate that there will be people reading this who feel compelled to say things along the lines of:
Actually, you are talking about Presentation/Domain /Application/Business/Data/Model/Whatever Logic, not Computation/Control Logic.
I addressed this problem in part at the beginning, but my general response to this is to say that I do not give a damn about the words themselves, but I do care about the things they point to. My goal was to discuss what I perceive to be the biggest conceptual gulfs between the kinds of logic that should be kept separate in a program. We all use different names for the same things, and the same names for different things and my only recourse is to define things anew in the context of what I am trying to teach. I will get in to further distinctions, and I do apply separation of Presentation/Domain/Data Logic in my projects, but that is not something I will get in to in a fundamentals series.
To the beginners reading this, be prepared to spend a lot of time reading and listening to arguments about these sorts of things; but please remember that the underlying concepts, and knowing what they mean in code, are what you should chase after.
Notes:
[1] It is worth mentioning that in a Von Neumann Architecture, the program’s instructions are also stored in the memory; not just variables and values which represent the problem domain.
Support
Follow the wiseAss Community:
https://www.instagram.com/wiseassbrand/
https://www.facebook.com/wiseassblog/
https://twitter.com/wiseass301
http://wiseassblog.com/
https://www.linkedin.com/in/ryan-kay-808388114
Consider donating if you learned something:
https://www.paypal.me/ryanmkay
