Programming Fundamentals Part 5: Separation of Concerns (Software Architecture)
This article series is based on rough drafts of what I intend to eventually turn into a series of lectures and course ware for my brogrammers and siscripters out there. Feedback is welcome, and if it proves useful, I would be happy to list you as a contributor.
2020 UPDATE: I have put together a course for Java which introduces the concepts I have described in these articles, but in greater depth and clarity. If you like my writing, I think you will love my video lectures:
Working Class Java: A Beginner’s Guide To OOP & Software Architecture Udemy Link| Skillshare Link w/ Free Trial
Contents
1. What Is A Program? — A set of instructions to be executed by an Information Processing System
2. The Problem Domain — How to design a program/application
3. Storing Information — How to Model Information (data) in an Information Processing System.
4. Logic And Errors — The two (primary) types of logic in an Information Processing System; how to handle errors properly
5. Separation Of Concerns — The most important Software Architecture principle I have ever come across
6. Proving Programs With Tests — An explanation of the theory, practice, and benefits of testing your software, and applying Test Driven Development
I would like to thank my friend and brogrammer Darel Bitsy (Medium: Darel Bitsy, Github: github.com/bitsydarel), for helping me to cement my understanding of separation of concerns. After several long discussion between us on the topic of Clean Software Architecture, it became quite evident to me that this quite possibly the most important principle to understand when it comes to designing and building programs.
In the previous article, my goal was to discuss the nature of Functions in Information Processing Systems (such as computers), and how there appear to be two primary distinctions of such Functions. With any luck, I did a decent job in explaining what these distinctions look like (along with some practical takeaways for error handling), but I did not go into any detail as to how one should go about keeping them separate; nor why I believe this is a very important thing to do.
In this article, I will not be discussing any particular facet of the three fundamental ingredients for any program (information stored in memory, computational logic, and control logic), but I will be discussing a principle which applies to all of the above; along with everything else. In fact, this principle is so powerful that I see it pop up regularly in just about everything I do, and have ever done.
With that in mind, I would encourage you to take a moment at the end of the article, to think about where you have, or could now, apply this principle in domains outside of programming. Connecting these concepts with familiar and simple analogies will help you to understand them greatly, and I will begin with one of the simplest analogies I could think of:
“Sidewalks” (or “Foot Paths” for those outside of NA). Do not worry, this will still help you write better programs.
Over-analyzing Everything Has Its Benefits
Some years ago, I was on my way to my job as a suit salesperson (I am not joking), and I found myself walking down a side-walk which had recently been replaced. While I am often at odds with the way in which my tax dollars are spent by the local government, this particular path was due for a replacement as it looked something like the picture below:

Now, as opposed to using one single continuous layer of asphalt or concrete, the replacement instead used a series of concrete squares, something like the picture below:

Being wired to ask questions from the most mundane to the most philosophical at all hours of the day (I am not bragging; it can be very annoying), I found myself briefly wondering what the benefit of separating a continuous sidewalk into sections might be:
- Supposing that a section was to become cracked or destroyed, one would only need to replace a single section to restore the sidewalk to its former shape and function
- One could build each segment of the sidewalk in isolation of the others
I will not carry this analogy further, but I would like you to keep it in mind as we now move to a more technical exposition of separation of concerns.
“Everything is teaching us.” — Teaching of Ajahn Chah
Separations In Graphical User Interface Applications
Several years ago, I set out to overview all of the different GUI architectural patterns which seemed to be popular (MVC, MVP, MVVM), with the intention of understanding what was similar and dissimilar between them. I naively expected everyone to share the same definitions of these different patterns (I hate to burst anyone’s bubble, but this is sadly not the case at all), and quickly became frustrated with all of the different articles and open source code bases I was pouring over.
If you would like a summary of what I have learned about software architecture over the years, check out: “The Perfect Model-View-Whatever Architecture.”
Eventually, I started to piece together that the common thread in most of these architectures (although plenty of programmers contradicted this idea), was a separation of three kinds of code:
- User Interface/View: Code which interacts with what the user sees, and can interact with
- Logic: Code which handles events and coordinates the flow of data between various parts of the program
- Data/Model: Code which is primarily concerned with storage and retrieval of real-world information (which I will refer to as “data” from here on)
With the exception of MVVM, where the term View-Model implies something to do with User interface and Data, yet is often filled with logic (I am not saying it is a bad pattern, but it is an atrociously bad name based on how most people use it), these three distinctions correlate fairly well to most three-layer architectures. For quite a long time, I referred to my architecture as Model-View-Presenter, but a turning point for my naming conventions was when another developer exclaimed that my architecture “looks a lot like Model-View-Controller.”
My first thought was that this confused onlooker needed to be educated on the subject of GUI architectures, but as I once again took a hard look at the differences between the two patterns, I became less enthusiastic about arguing the point. In fact, after learning that MVC has meant many different things over the years (originally coined by Trygve Reenskaug), I finally decided that the only solution was to start using the words I thought best described my architecture instead.
My goal in doing so, and in discussing them in this article, is not to get you to start using my words, as that will only confuse the issue further. However, please pay close attention to the underlying concepts behind the words; which I do believe my words may do a better job of pointing therein.
In any case, I will now discuss the separation of concerns as applied to three different perspectives of software architecture:
- Functions/Methods/Algorithms
- Things/Classes/Objects
- Modules/Components/Sub-systems/Packages
Separation Of Functions
Separation of functions can be summarized by the following statement: Try not to write giant functions.
The following code samples are written in Kotlin, but they should be easily intelligible if you have any experience in writing programs in most modern languages. Also note that I have deliberately not used constructs such as “data classes,” and “objects,” and “return when” for the sake of keeping this simple to read for those who may not be familiar with the language. If you would like a beginner’s introduction to Kotlin, check out this video (only a browser is required to follow along).
The following function accepts three String arguments (Strings are collections of characters, numbers, and symbols such as “Hello World” or “14.500001”), checks whether they are valid to be used as a mathematical expression and if so, returns a String result of evaluating this expression. If any of the arguments are not valid, it returns a String error message:
/* To represent a mathematical binomial expression, we will use this class (a "class" is Kotlin's version of a "Thing" as discussed in Part 3*/class Expression(
val operandOne: Double,
val operandTwo: Double,
val operatorSymbol: String
)/**
* Returns the result of a valid binomial expression, or an error message if the expression is invalid
*/
fun solveBinomialExpression(operandOne: String,
operandTwo: String,
operatorSymbol: String): String {
//1 Validate arguments (toDoubleOrNull is a function within the Kotlin Standard Library)
val ERROR_MESSAGE = "An error has occured."
if (operandOne.toDoubleOrNull() == null) return ERROR_MESSAGE
if (operandTwo.toDoubleOrNull() == null) return ERROR_MESSAGE
val expression: Expression
when (operatorSymbol) {
"+" -> expression = Expression(operandOne.toDouble(), operandTwo.toDouble(), operatorSymbol)
"-" -> expression = Expression(operandOne.toDouble(), operandTwo.toDouble(), operatorSymbol)
"*" -> expression = Expression(operandOne.toDouble(), operandTwo.toDouble(), operatorSymbol)
"/" -> expression = Expression(operandOne.toDouble(), operandTwo.toDouble(), operatorSymbol)
else -> return ERROR_MESSAGE
}
//2 Calculate Result
when (expression.operatorSymbol) {
"+" -> return (expression.operandOne + expression.operandTwo).toString()
"-" -> return (expression.operandOne - expression.operandTwo).toString()
"*" -> return (expression.operandOne * expression.operandTwo).toString()
"/" -> return (expression.operandOne / expression.operandTwo).toString()
else -> return ERROR_MESSAGE
}
}
Whether or not you are fluent in Kotlin, the above function is pretty ugly. It concerns itself with validating the three different arguments (operandOne, operandTwo, operatorSymbol), and calculating their results. Believe it or not, this is quite a tame example compared to many code bases I have seen.
In the next example, observe that we have divided this single function, into a primary function, with a series of “helper functions:”
class Expression(
val operandOne: Double,
val operandTwo: Double,
val operatorSymbol: String
)//Error message has been defined outside of our primary functionconst val ERROR = "An error has occured."/**
* Returns the result of a valid binomial expression, or an error message if the expression is
* invalid */
fun solveBinomialExpression(args: Array<String>): String {//Looks cleaner and more legible in my estimation
val expressionResult = validateArguments(args[0], args[1], args[2])
if (expressionResult == null) return (ERROR)
else return evaluateExpression(expressionResult)
}//this function, might return an expression, or it might return "null"
//if the arguments are valid, we return expression; else return null
fun validateArguments(operandOne: String, operandTwo: String, operatorSymbol: String): Expression? {
if (operandOne.toDoubleOrNull() == null) return null
if (operandTwo.toDoubleOrNull() == null) return null
return when (operatorSymbol) {
"+" -> Expression(operandOne.toDouble(), operandTwo.toDouble(), operatorSymbol)
"-" -> Expression(operandOne.toDouble(), operandTwo.toDouble(), operatorSymbol)
"*" -> Expression(operandOne.toDouble(), operandTwo.toDouble(), operatorSymbol)
"/" -> Expression(operandOne.toDouble(), operandTwo.toDouble(), operatorSymbol)
else -> null
}
}fun evaluateExpression(expression: Expression): String {
return when (expression.operatorSymbol) {
"+" -> (expression.operandOne + expression.operandTwo).toString()
"-" -> (expression.operandOne - expression.operandTwo).toString()
"*" -> (expression.operandOne * expression.operandTwo).toString()
"/" -> (expression.operandOne / expression.operandTwo).toString()
else -> ERROR_MESSAGE
}
}
As you can see, it is not that we have gotten rid of the ugly validation and evaluation logic; we have hidden the ugly stuff behind helper functions based on what that logic is concerned with. This allows solveBinomialExpression(…) to act as a control logic based function which delegates computational logic to helper functions.
The above example is of trivial complexity for ease of understanding, but this approach is particularly important when dealing with more complex problems that need to be solved. Not only can we make our code more legible by doing so (assuming we give good names to our helper functions), but we have also decomposed one large, difficult to test function, into several small, easy to test functions. Testing is the subject of the next article, and it is important!
Separation Of Things
The previous section took a more functionally based approach to solve that particular problem, but we can apply this same principle in a more object-oriented approach. Fortunately, Kotlin is a multi-paradigm language which allows us, programmers, to apply different approaches as we see fit:
data class Expression(
val operandOne: Double,
val operandTwo: Double,
val operatorSymbol: String
)
const val ERROR_MESSAGE = "An error has occured."
fun main(args: Array<String>) {
val expressionResult = Validator.validateArguments(args[0], args[1], args[2])
if (expressionResult == null) println(ERROR_MESSAGE)
else { Printer.printExpression( Calculator.evaluateExpression(expressionResult)
)
}
}
class Printer {
fun printExpression(result: String) = System.out.println(result)
}
class Validator {
fun validateArguments(operandOne: String, operandTwo: String, operatorSymbol: String): Expression? {
if (operandOne.toDoubleOrNull() == null) return null
if (operandTwo.toDoubleOrNull() == null) return null
return when (operatorSymbol) {
"+" -> Expression(operandOne.toDouble(), operandTwo.toDouble(), operatorSymbol)
"-" -> Expression(operandOne.toDouble(), operandTwo.toDouble(), operatorSymbol)
"*" -> Expression(operandOne.toDouble(), operandTwo.toDouble(), operatorSymbol)
"/" -> Expression(operandOne.toDouble(), operandTwo.toDouble(), operatorSymbol)
else -> null
}
}
}
class Calculator {
fun evaluateExpression(binomialExpression: Expression): String {
return when (binomialExpression.operatorSymbol) {
"+" -> (binomialExpression.operandOne + binomialExpression.operandTwo).toString()
"-" -> (binomialExpression.operandOne - binomialExpression.operandTwo).toString()
"*" -> (binomialExpression.operandOne * binomialExpression.operandTwo).toString()
"/" -> (binomialExpression.operandOne / binomialExpression.operandTwo).toString()
else -> ERROR_MESSAGE
}
}
}Again, note that we have separated all of the conceptually different functions which we must perform, and created a class to encapsulate them. Each class is concerned with a particular operation, such as printing the result to the console (via println()), validation logic, evaluation logic, and our primary function still coordinates the flow of data between these different things.
To briefly demonstrate how this principle could be applied in a more complicated application, observe the following separations which I like to employ in a given feature of my applications. A feature is a distinct “screen” or “flow” of an application, such as “Profile”, “Home”, “Find Friends”, “Messenger”, and so forth within the Facebook application:

It would take too long to go through all of these different files in detail, but I will briefly describe each of their roles as distinct “Things” in SpaceNotes (all code is available open source here):
- buildlogic is a sub-package which contains the code necessary to wire all of these different things together at run time
- INoteDetailContract specifies the different interactions between classes and the events which may occur in this particular feature
- NoteDetailActivity is a feature level “container”, within which these different things are deployed in to (it is also the entry point of the feature)
- NoteDetailLogic is the “decision maker” of the feature, which handles the events and interactions specified in the contract (this kind of class is the most important to test)
- NoteDetailNavigator contains logic which can be used to navigate to other features
- NoteDetailView contains logic and bindings to the user interface
- NoteDetailViewModel contains the most recent data which has been returned from the “backend” of the application (or data which is passed into the feature via navigation), and persists this data so that the logic class or view does not need to (if they did, it would break the separation of concerns)
As you can see, I have gone well beyond simple MVC/MVP/MVVM in my front end architectures. Instead, I pick and choose what Things I need based on what is required for the feature at hand. If you visit the repository and check out the notelist feature, you will see other Things such as adapters present.
Separation Of Modules
Regrettably, “module” is another word which is not used consistently across platforms/languages/programmers. In this instance, a “module” is a very broad grouping of Things which are related to a particular broad concern. We are getting into quite advanced territory which you will not need to cover unless you plan on building complex multi-platform GUI applications, but I will briefly discuss the different modules present in SpaceNotes:
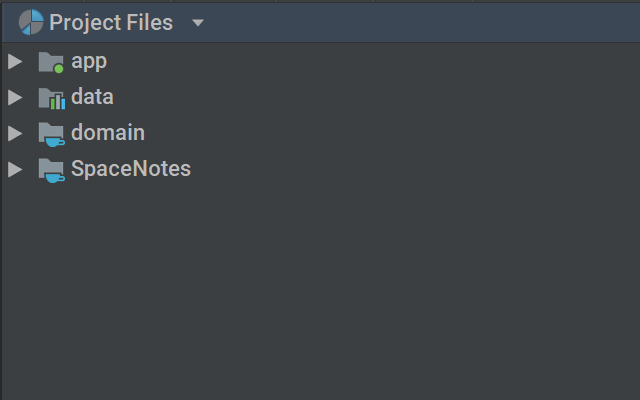
- app is a “front-end android” module, which contains the classes we saw in the previous section. I will eventually include a “front-end web” module, which is why I have separated things thus.
- domain is a platform/third-party-library independent module which describes data classes, backend repositories, interactors, and so forth. It provides a high-level description of the application’s problem domain and also serves as a point of commonality between the different platform modules.
- data is a “back-end android” module, which contains repository implementations (databases, both on the device and remotely stored via Firebase cloud service).
Why Bother Doing This?
The majority of programmers, unfortunately, do not observe separation of concerns:
- At the level of Functions, they write Spaghetti Code
- At the level of Things, they write God Classes/Objects
- At the level of the entire architecture of their systems, they write Monoliths
This is regrettably the most common way of doing things, and the general rationale for doing so is that it can actually be really difficult to achieve separation of concerns and to build modular systems. As usual, many people assume that the short-term easy path which does not require studying difficult concepts and ideas will get them to their goals at a faster pace. What these people will not realize (unless they change their ways), is the enormous benefits which are provided from building programs in this way:
- They are easier to read, which will save you and your team plenty of time which would otherwise be spent deciphering code which you wrote even days prior.
- They are easier to modify, fix, and update, as you are working with individual units of code (we could be talking, functions, things, or modules); as opposed to continuous and amorphous blobs of code. Think back to my sidewalk analogy.
- They are easier to test.
- They actually are easier to design and build. This is perhaps the greatest irony: Some people actually think it is easier to build complex programs without any architecture (it makes sense if do not think about it).
Separation of concerns, which is the key to any good software architecture (whatever you choose to call it), is worth it, and I strongly encourage you to apply it as often as possible in your code bases.
Support
Follow the wiseAss Community:
https://www.instagram.com/wiseassbrand/
https://www.facebook.com/wiseassblog/
https://twitter.com/wiseass301
http://wiseassblog.com/
https://www.linkedin.com/in/ryan-kay-808388114
Consider donating if you learned something:
https://www.paypal.me/ryanmkay
